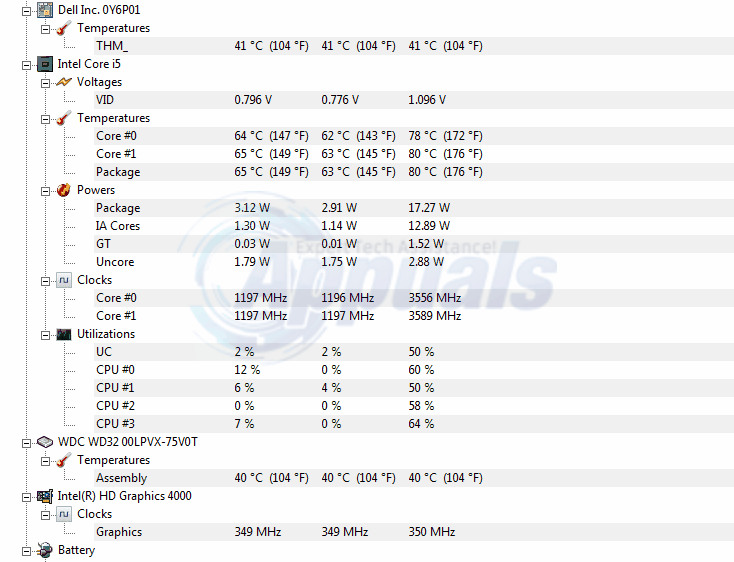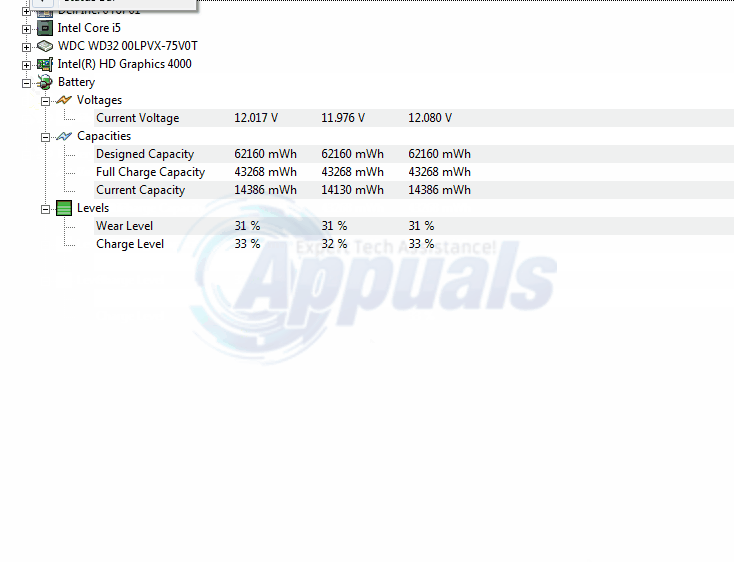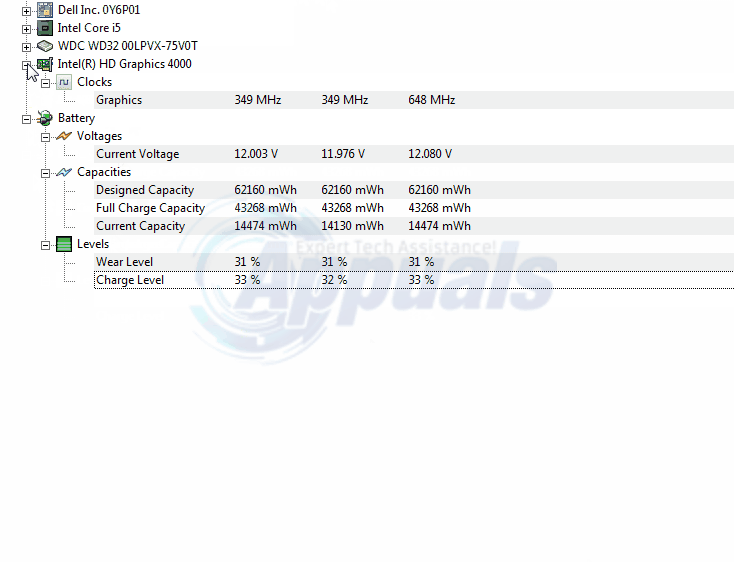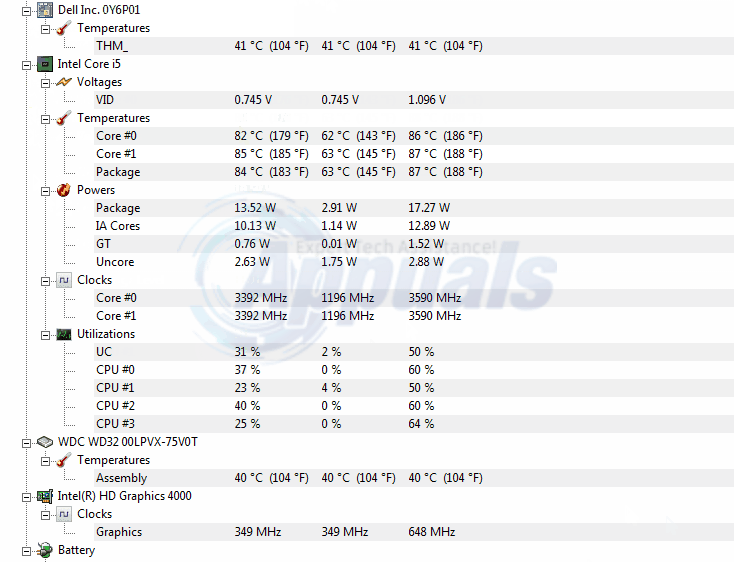
Projektując obiekty w SQL Server, musimy przestrzegać pewnych najlepszych praktyk. Na przykład tabela powinna mieć klucze podstawowe, kolumny tożsamości, indeksy klastrowe i nieklastrowane, integralność danych i ograniczenia wydajności. Tabela programu SQL Server nie powinna zawierać zduplikowanych wierszy zgodnie z najlepszymi praktykami w projektowaniu baz danych. Czasami jednak musimy zajmować się bazami danych, w których te zasady nie są przestrzegane lub w których możliwe są wyjątki, gdy reguły te są celowo omijane. Mimo że postępujemy zgodnie ze sprawdzonymi metodami, możemy napotkać problemy, takie jak zduplikowane wiersze.
Na przykład moglibyśmy również uzyskać tego typu dane podczas importowania tabel pośrednich i chcielibyśmy usunąć zbędne wiersze przed faktycznym dodaniem ich do tabel produkcyjnych. Ponadto nie powinniśmy pozostawiać możliwości powielania wierszy, ponieważ zduplikowane informacje umożliwiają wielokrotną obsługę żądań, nieprawidłowe wyniki raportowania i nie tylko. Jeśli jednak mamy już zduplikowane wiersze w kolumnie, musimy zastosować określone metody, aby oczyścić zduplikowane dane. Przyjrzyjmy się kilku sposobom w tym artykule, aby usunąć powielanie danych.

Tabela zawierająca zduplikowane wiersze
Jak usunąć zduplikowane wiersze z tabeli programu SQL Server?
W SQL Server istnieje wiele sposobów obsługi zduplikowanych rekordów w tabeli w oparciu o określone okoliczności, takie jak:
Usuwanie zduplikowanych wierszy z unikatowej tabeli indeksu programu SQL Server
Możesz użyć indeksu do sklasyfikowania zduplikowanych danych w unikalnych tabelach indeksu, a następnie usuń zduplikowane rekordy. Po pierwsze, musimy stworzyć bazę danych o nazwie „test_database”, a następnie utwórz tabelę „ Pracownik ”Z unikalnym indeksem za pomocą kodu podanego poniżej.
UŻYJ master PRZEJDŹ STWÓRZ BAZĘ DANYCH test_database PRZEJDŹ UŻYJ [test_database] PRZEJDŹ STWÓRZ TABELĘ Pracownik ([ID] INT NOT NULL IDENTITY (1,1), [Dep_ID] INT, [Imię] varchar (200), [e-mail] varchar (250) NULL , [miasto] varchar (250) NULL, [adres] varchar (500) NULL CONSTRAINT Primary_Key_ID PRIMARY KEY (ID))
Wynik będzie taki, jak poniżej.

Tworzenie tabeli „Pracownik”
Teraz wstaw dane do tabeli. Wstawimy również zduplikowane wiersze. „Dep_ID” 003,005 i 006 to zduplikowane wiersze z podobnymi danymi we wszystkich polach z wyjątkiem kolumny tożsamości z unikalnym indeksem klucza. Wykonaj kod podany poniżej.
UŻYJ [test_database] PRZEJDŹ WSTAW DO pracownika (ID_ Depozytu, imię i nazwisko, adres e-mail, miasto, adres) WARTOŚCI (001, 'Aaaronboy Gutierrez


![TeamViewer oferuje bezpłatny dostęp niektórym użytkownikom biznesowym z powodu koronawirusa [nieoficjalnie]](https://jf-balio.pt/img/news/62/teamviewer-offers-free-access-some-business-users-due-coronavirus.jpg)









![[FIX] Netflix nie wyświetla filmów w 4K](https://jf-balio.pt/img/how-tos/95/netflix-not-showing-videos-4k.jpg)